
With the rise of Large Language Models (LLM), organizations have suddenly realized that they can now have an actual chat with their vast trove of unstructured data.
For decades now, organizations, public and private, have been sitting on terabytes of files, notes and emails, buried more or less deeply into the depths of their cloud drives or email servers. The knowledge hidden there may just be an untapped treasure, they now realize, holding information potentially capable of unlocking a win during the next sales cycle, or perhaps revealing some profound forgotten knowledge that could just give that extra push to the bottom line… What really hides in this dark ocean that holds 80 to 90% of the organization’s data? And besides, who has access to those files ? Isn’t there a forgotten public folder somewhere holding some of the keys to the kingdom? And since we’re at it, what was Alice working on before she left the company ?
Great questions, which have been so far impossible to answer. Yet everything seems possible now with the advent of GenAI…
The idea behind “talking to the data” is to use a LLM as one’s intermediary: “just” make a LLM “look” at that data and answer questions about it, simple! And the way to do this nowadays is to use a chat-enabled Retrieval-Augmented Generation (RAG) type of application. Well, much easier said than done, as 95% of GenAI pilots fail to generate any value, RAG projects being no exception, unfortunately.
When implementers start working on the problem, the first challenge they face is that this unstructured data must be retrieved somehow, and fed to the LLM. But in order to fetch the data that is relevant to the user’s prompt, that data must first be made sense of. The data source is a collection of files and/or folders, created by various users over the years, each with their own content and ideas about how to organize it; how to even go about it? Besides, one can’t just load everything and cram it into an LLM, there’s just too much data, probably tens of millions of files, depending on the size of the organization. The first challenge is therefore to collect this data and add some measure of structure to it.
The second problem is that when this data has been properly loaded, labeled and made sense of, it must also be protected. As we know, LLMs can be tricked in many ways, it would be nice to not just expose trade secrets or top secret blueprints to anyone with a clever prompt…
The third problem is that organizations are dynamic entities, they change over time and have processes that must be adhered to. This RAG system must therefore also be able to adapt to change and comply with the organization’s workflows and policies. These must be respected even when these processes or policies change. Leavers must lose access, some joiners may gain access, new documents must be made available, and maybe some of the data should also be exposed to other non-human things or processes.
Let’s have a closer look and see how to solve these problems…
Structuring the unstructured
According to Wikipedia, “graphs have more recognizable structure than strings of text and this structure can help retrieve more relevant facts for generation. Sometimes this approach is called GraphRAG.”
A good idea here is to take this unstructured data and store it as a graph. Graphs have this uncanny ability to help make sense of complexity. They are the natural way that we, humans, represent our ideas, memories and in general, knowledge. Graphs represent context accurately by highlighting the relationships between entities. Showing how things relate to each-other helps us manage this complexity and navigate chaos. This networked context is then invaluable in providing relevant answers to the questions asked by the prompting user.
At this point we can pause, and ponder how fortunate it is that all data is fundamentally relational, even the unstructured kind. Data is only "unstructured" for two reasons:
- It is not properly labelled: i.e., not much describes what it actually is, and
- The relationships between the data elements and the various entities that interact with them are hidden or not obvious.
But the data does in fact describe some thing or things, those cloud drive documents are in fact related to folders, organizations, groups and users, these properties are just hidden and must be discovered. That is the essence of the first challenge: uncovering these relationships and making them plain. Now, we can tackle this challenge by cheating a bit: we have knowledge that can help us make sense of this chaos when we consider data stored in cloud drives:
- Folders have hierarchies.
- Files in the same folder probably share some common properties, themes or are related in some way.
- Cloud providers and organizations have Authorization systems that drive access to cloud drives or files, generally through Role-Based access control systems.
Based on these, we can draw a mind map, a graphical representation of what we expect this overall mess to actually look like; maybe something akin to this:
User -> Group -> Folder -..*..-> Folder -> File
This describes a graph: it is a graph schema. We could build a full blown graph by just following the guidelines expressed in this schema: Users can be members of Groups. Group members may be able to access Folders or Files. Folders may hold other folders or files.
It is now “just” a matter of pulling the data from all the various source systems, from Users, then Groups all the way to individual files, labelling it as we go, based on what is being read, and additionally applying some magic proprietary sauce to add semantic tags based on content to it if possible. Extracting the relationships from the source data means revealing these links from the hidden ways they are represented there: possibly as attributes or metadata. We can then create this knowledge graph.
Defying prompt engineering with Permission-Aware retrieval
Once the unstructured has become structured, the permissions become obvious: they are realized through the relationships between the nodes created during the data ingestion phase. At this point, one can just follow these connections between any Subject and Resource to understand who can actually access what. This realization alone can be invaluable for any organization, as, again, these entitlements are typically hidden and invisible when spread across several source systems.
Now given that the Cloud drives generally use variants of Role-Based Access Control (RBAC), with access being driven by data Ownership, or by Group and/or Role memberships, simple Relationship-Based Access Control (ReBAC) is typically sufficient to enforce access in the resulting graph. ReBAC just uses the relationships between objects: if a path exists between Subject and Resource, then access is granted. The access policies from the source systems can therefore be realized by simple path definitions in the graph-based system.
Besides, new policies could also be added to the ones discovered in the source systems, conditions involving attributes even, thus implementing Attribute-Enhanced ReBAC (AReBAC). What matters here is that this authorization system must use a set of deterministic rules. We can’t trust AI models to enforce access control themselves: given any input, we must be able to determine with certainty what the output will be. This makes the system provable and thus ensures compliance to standards and regulations. Access Policies must therefore be set in stone, providing predictable, provable and auditable outputs for any input.
Given the now-structured data and this deterministic access control system, it is now possible to implement Permission-Aware Semantic Searches (PASS). To do this, we first set the Subject in each request to be the User or Non-Human entity making the prompt. The authorization system will just evaluate the Subject’s access during the retrieval phase, and only return the data that the Subject is entitled to see. The RAG client itself should have no access at all by default: left to its own devices that system can’t retrieve or do anything, it needs a prompt.
The Retrieval process can use various techniques, such as vector searches or GraphRAG. In fact, the GraphRAG approach has been shown to outperform the regular vector-RAG methods, precisely because it uses whole subgraphs of closely-related nodes rather than just unique data points. In any case, regardless of the method used, the set of nodes semantically close to the Subject’s prompt must be compared to the set of nodes the Subject is actually entitled to access; the intersection of these two sets is the retrieval data that can be fed as context to the LLM in order to generate the final answer.
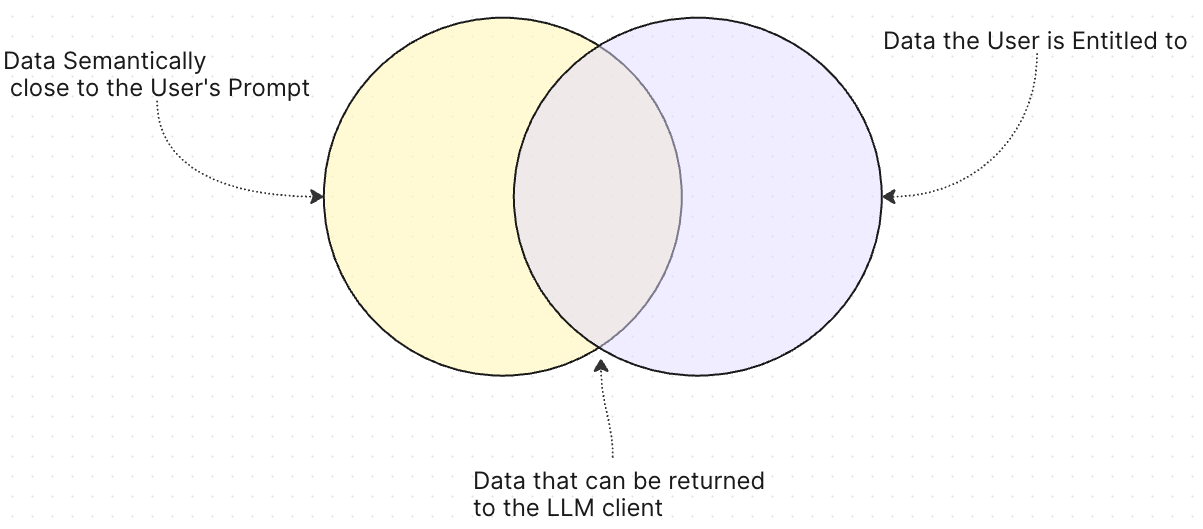
Figure 1 - The intersection of Semantic and Permitted data sets
Now this system is impervious to adversarial or engineered prompts attacks, because the authorization system filters the data through a set of deterministic rules. Prompts can change the nature or contents of the Semantic set (Yellow set in figure 1 and 2), but the Entitlement set (Purple set in Figure 1 and 2) doesn’t change: it is always produced by those of pre-defined, very deterministic rules that are unrelated to the prompt, and will therefore always provide the same answers given the same Subject and Access Policies.
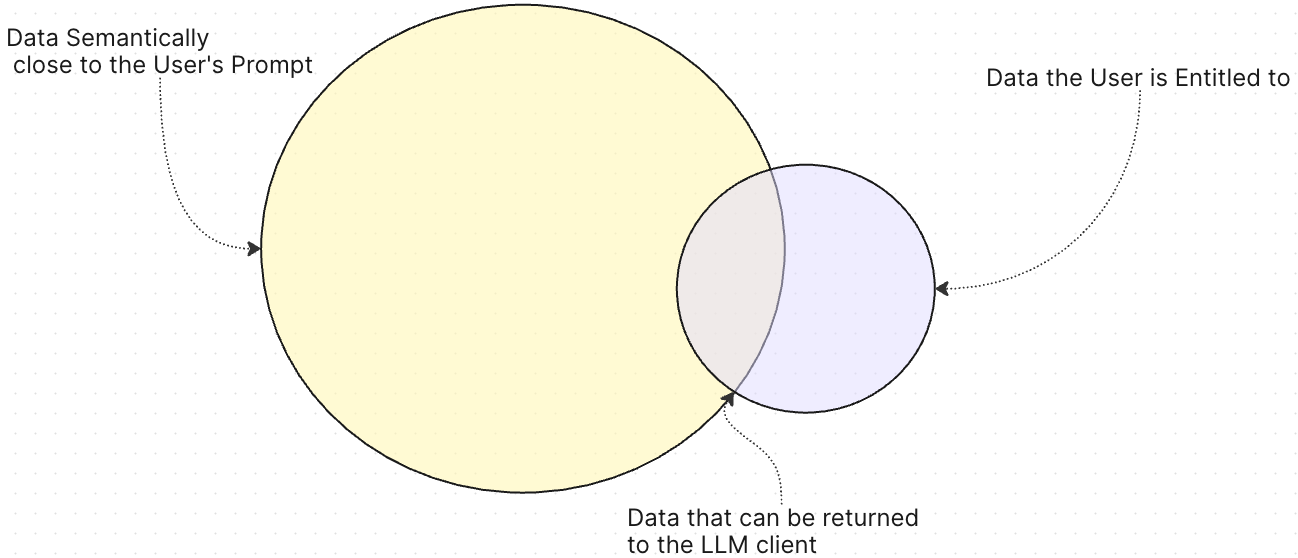
Figure 2 - A clever prompt enlarged the size of the Semantic match data set, yet the Permitted data set didn’t change.
The intersection of both sets can therefore only ever contain permitted data, regardless of any prompt attack. It is thus impossible for the prompting entity to ever retrieve data they are not entitled to access.
Fitting an organization’s ecosystem
The last piece of the puzzle is dynamicity. Changes happen all the time in any organization, these changes must be reflected in the RAG system, ideally in close to real-time. Changes can pertain to the business rules or policies, to the data itself, to the users or to any of the various systems integrated with the graph.
There are many ways to achieve dynamic updates, but the best practices nowadays seem to favour real time events. Events can cause system updates, propagate changes or even trigger workflows, supporting Event streams is therefore crucial.
In addition to supporting events, our RAG system should also be easily configurable and manageable, in such a way that the deterministic access policies it relies upon can be modified when needed, even programmatically. Such a system should also embrace open standards for ease of integration and future proofing. Now this seems like a lot, lucky though such a system actually exists, Welcome to RAGProtect!
Want to learn more? Get the RAG Security E-Guide.










